Technology tamfitronics
Science is frequently subject to the Gartner hype cycle1: emergent technologies spark intense initial enthusiasm with the recruitment of dedicated scientists. As limitations are recognized, disillusionment often sets in; some scientists turn away, disappointed in the inability of the new technology to deliver on initial promise, while others persevere and further develop the technology. Although the value (or not) of a new technology usually becomes clear with time, appropriate benchmarks can be invaluable in highlighting strengths and areas for improvement, substantially speeding up technology maturation. A particular challenge in computational engineering and artificial intelligence (AI)/machine learning (ML) is that benchmarks and best practices are uncommon, so it is particularly hard for non-experts to assess the impact and performance of these methods. Although multiple papers have highlighted best practices and evaluation guidelines2,3,4the true test for such methods is ultimately prospective performance, which requires experimental testing.
In the 1990s, several groups attempted to predict the structures of proteins from amino acid sequences, and the success and value of different models were assessed ad hoc. The Critical Assessment of Structure Prediction (CASP)5 biannual competition was established in 1994 to compare the performance of various algorithms. In this competition, teams used experimental methods (predominantly X-ray crystallography and NMR) to determine protein structure, but supplied only the protein sequences to the modeling community. Expert modeling teams then used either a combination of human expertise and computational methods or fully automated methods to predict the correct structure from the sequence. Teams were allowed to provide up to five models per target. An independent panel compared the predicted and experimentally determined structures. Widely viewed as the ‘protein structure prediction world championship’, the competition demonstrated incremental improvements in structural predictions until AlphaFold6 won dramatically in 20187 and 20208. Although AlphaFold has not competed since, many methods today are inspired by the AlphaFold architecture, collectively demonstrating the power of deep learning algorithms for protein structure prediction. Other, similar competitions aimed at predicting antibody structure from sequence9,10 were initiated but have not been held since 2014.
Thirty years after CASP was launched, the application of AI/ML solutions and other in silico approaches to the development and improvement of proteins11particularly antibody therapeutics12,13,14has led to a desire to understand the capabilities of these technologies. Numerous companies and academic groups claim AI/ML solutions to affinity maturation, antibody developability and de novo antibody and library design. However, there remain substantial challenges in understanding the value of these algorithms: how they differ from one another in performance, how the quality of predicted antibodies compares to that of antibodies derived from existing experimental practices, how effective the algorithms are in generating antibodies recognizing particular epitopes (including experimentally more challenging targets such as those with membrane, glycan or flexible components), how generalizable they are and, in particular, whether they are able to provide antibodies with the desired properties more rapidly than experimental approaches. Most results are based on retrospective studies (that is, studies without new experiments) and are performed without making data accessible. This limits the validation of such claims and the real-world impact of these methods. ML methods can perform very differently in prospective studies compared to retrospective ones, for example, in docking onto AlphaFold2-generated structures15. Yet prospective evaluations of new problems are essential to assess real-world performance. These difficulties emphasize the importance of a public and prospective benchmarking effort to provide a quantifiable, unbiased assessment of these techniques. Here, we propose the launch of an AI/ML benchmarking exercise (named AIntibody and accessed via the eponymous AIntibody.org website) that will present a series of escalating AI/ML challenges in antibody discovery, calibrated according to the success of the outcomes of previous competitions.
Launching an AI/ML benchmarking competition
The AIntibody competition aims to validate the performance of computational models, including those based on AI, to generate antibody candidates. Teams are invited to submit antibody sequences in response to the challenges described below. Submitted sequences will be synthesized as proteins and independently benchmarked in a wet lab. The long-term goal is to produce an ongoing challenge series analogous to CASP. As the competition evolves, the challenges are expected to become progressively more difficult, and each will be followed by a peer-reviewed manuscript to provide the community with clarity about the results, highlighting areas for improvement and satisfactory capabilities.
In addition to CASP, this competition has similarities to the Critical Assessment of Computational Hit-finding Experiments (CACHE)16Drug Design Data Resource (D3R) Grand Challenge17 and Statistical Assessment of Modeling of Proteins and Ligands (SAMPL)18. CACHE is an extensive public–private partnership benchmarking initiative recently established to enable the development of computational methods for drug hit-finding and to address the problem that no “algorithm can currently select, design or rank potent drug-like small-molecule protein binders consistently.” The D3R Grand Challenge focuses on the prediction of (small-molecule) ligand–protein pose and binding affinity, whereas SAMPL conducts blind prediction challenges in computational drug discovery, with an emphasis on binding modes, affinities and physical properties for small molecules. Unlike these small-molecule-related competitions, the AIntibody competition is focused on antibodies and follows different organizing principles.
Given the urgent need for benchmarking in AI/ML-mediated antibody discovery, this first competition is an unfunded ad hoc contest based on datasets generated against the receptor-binding domain (RBD) of SARS-CoV-2 by some of the authors and made available to participants and the broader scientific community, with participants paying a significantly discounted fee ($120/antibody) to cover the costs of gene synthesis and expression of each submitted antibody sequence. As the responses are designed to test the present immediate value of AI/ML algorithms, participants will have 14 days from data access to provide sequence solutions. This timeframe is designed to prevent experimental validation before submission; validation will be carried out independently and conducted blindly by third parties. The structure of the supplied data can be found in Tables 1 and 2, allowing participants ample time to prepare in advance. We anticipate that the ad hoc nature of this first competition will provide deeper understanding and time to organize future contests through more formal partnerships or societies, involving steering committees comprising academic and industry scientists, ideally with external funding.
Full size table
Full size table
Testing antibodies for biological activity is complex; however, the challenges presented in this inaugural competition are relatively straightforward, involving only affinity and developability (Table 3), which are the subjects of many AI/ML state-of-the-art performance claims and are among the most important determinants of biological activity. Results will be published blinded. Although it is not obligatory, participants will be invited to be co-authors on published results papers, akin to the approach taken recently in an analysis of diverse antibodies against SARS-CoV-219. Participants will be able to see the range of results and their ranking within that range, but individual performances will remain masked. For each challenge described below, the focus lies in engineering only the complementarity-determining regions (CDRs; the IMGT.org definition is used for all CDRs except the LCDR2, for which the Kabat definition is used). For example, frameworks of the antibodies provided in the datasets should not be modified within the context of the challenge. Although in vivo affinity maturation is focused on CDRs, framework mutations are often also introduced. The challenges introduced here limit available diversity space to CDRs, providing a direct comparison to experimental methods20. Future challenges may allow the introduction of framework mutations.
Full size table
This benchmarking exercise will help us to understand the power of AI/ML capabilities applied to antibody discovery at this time. The results of the competition will provide insight for establishing realistic timelines for future AI/ML use in antibody discovery.
Competition details and guidelines
The challenges proposed in this inaugural competition are based on unpublished SARS-CoV-2 next-generation sequencing (NGS) datasets from which some antibodies were characterized21,22. Given the vast amount of additional public data available for SARS-CoV-2–binding antibodies (for example, in COVIC19 and Cov-AbDab23), the following should provide the best possible scenario for AI/ML task success.
Once designed or identified sequences have been uploaded, Azenta will synthesize up to 1,200 genes for antibodies, express and purify them, carry out size-exclusion chromatography and provide coded antibodies to other partners. Antibody affinities will be assessed by Carterra using surface plasmon resonance (LSA-XT) and by Sapidyne using the kinetic exclusion assay (KinExA) for the strongest binders. Mosaic will assess developability (hydrophobic interaction (HIC) high-performance liquid chromatography (HPLC), baculovirus particle (BVP) enzyme-linked immunosorbent assay (ELISA), affinity-capture self-interaction nanoparticle spectroscopy (AC-SINS), Tm and Tagg). Bio-Techne will provide the target. These assays will ensure standardized conditions and unbiased head-to-head comparison of predicted sequences.
Competition 1: In silico antibody affinity maturation
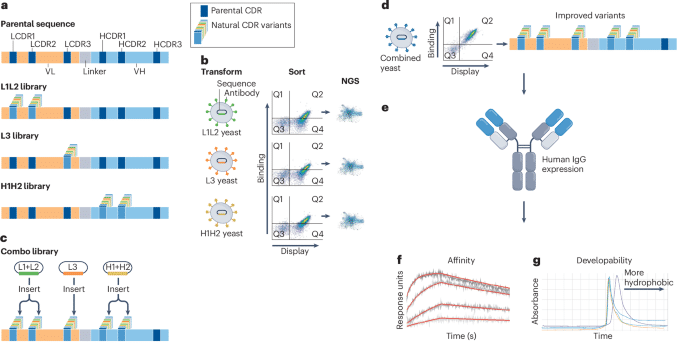
Participants will be provided with experimental datasets derived from the affinity maturation of an antibody recognizing the RBD of SARS-CoV-2 (Table 1). Each dataset comprises three NGS sub-datasets of CDR sequences (LCDR1+2, LCDR3 and HCDR1+2, in which the remaining CDRs are constant) generated during phase 1 of a previously described experimental affinity maturation method20 (Fig. 1), in which phase 2 involves combining all phase 1 outputs and experimentally selecting for higher affinity. Each antibody population has diversity only in the indicated CDRs (Fig. 1a), with the remaining CDRs being parental, and has been displayed on yeast and sorted for target binding (Fig. 1b). Although each population binds the target more tightly tha n the parental population, individual NGS sequences have not been assessed for their ability to encode antibodies with improved binding activity and may include PCR or sequencing errors. Although amino acid sequences of phase 2–characterized antibodies with their affinities have been determined (Fig. 1c,d), these data will not be provided, so that the computational methods are given the opportunity to generate the same (or better) sequences.

aPhase 1: DNA library diversity is introduced into L1+L2, L3 or H1+H2 of an anti-RBD scFv. bSelective pressure is applied by FACS using RBD to select for improved binders. cPhase 2: RBD binding diversity from each of the three arms (L1+L2, L3, H1+H2) is recovered, PCR-amplified and recombined into a yeast display vector. dThe combined diversity is transformed back into yeast and sorted for improved affinity and expression. e–gSequencing identifies final improved variants, which are reformatted into IgG for expression (e), binding affinity (f) and developability (g) measurements.
Full size image
The computational goal of Competition 1 is to design antibodies (Fig. 1e) with improved affinity (Fig. 1f) for the RBD of SARS-CoV-2 that also exhibit favorable developability properties (Fig. 1g) using the NGS datasets. Designs should be applied to only heavy chain complementarity determining regions 1 and 2 (HCDR1–2) and light chain complementarity determining regions 1, 2, and 3 (LCDR1–3) and not to frameworks or heavy chain complementarity determining region 3 (HCDR3). The blinded assessment will determine the affinities of the designed antibodies and how well they compare to those of the antibodies obtained experimentally in phase 2. Although the experimental affinity maturation was carried out on single-chain variable fragments (scFvs) displayed on yeast, antibodies were, and will be, tested as full-length IgGs. Results will be compared to the affinities of experimentally derived sequences generated by combining the three phase 1 outputs and selecting from the corresponding combinatorial library displayed on yeast.
Competition 2: In silico affinity rank prediction for antibody discovery
Participants will be provided with an NGS dataset of a single selection output recognizing the RBD of SARS-CoV-2, clustered by HCDR3 sequence22 using a previously published library24which comprises natural CDRs embedded within well-behaved therapeutic scaffolds. Although not all individual NGS sequences have been assessed for their ability to encode antibodies with binding activity, and therefore they may include PCR or sequencing errors, those sequences encoding antibodies (as IgG) demonstrated to bind the target will be identified or provided, with their corresponding affinities. Furthermore, the relative frequency of different sequences within the clusters will be provided; see Table 2 for a representative dataset.
The computational goal of Competition 2 is to identify those sequences within the existing NGS dataset that encode the highest-affinity antibodies (that have not already had their affinities determined) in the two largest HCDR3 clusters, by largest number of VL+VH sequences, from experimental bin group 1 (that is, 28F and 27F) and the largest cluster from experimental bin group 2 (that is, 47F; Table 4). Results will be compared to the affinities of those antibodies that were experimentally derived and for which sequences were provided.
Full size table
Competition 3: NGS-inspired computational antibody design
Participants will be given the same NGS output as in competition 2. The AI/ML goal is to generate out-of-library sequences of antibodies binding the same target with as high affinities as possible that also exhibit favorable developability properties, using the provided NGS datasets described here and any other useful publicly available data. Only CDRs should be designed, and frameworks should remain unmodified (Table 2). The out-of-library sequences should not be present within the NGS dataset itself, nor be derived from any previous independent experiments. Results will be compared to the affinities of those antibodies that were experimentally derived and for which sequences were provided.
Each of these challenges has high affinity as an endpoint, but developability will also be assessed to ensure that affinity is not generated at the expense of developability. Antibodies will be judged as passing, questionable or failing on each of the five developability assays described above, with failing antibodies scored 2, questionable antibodies scored 1 and passing antibodies scored 0; any antibody with a total score of 4 or above will be considered failing.
Publication of results and participation requirements
Participants agree to make the winning algorithm (from each of the three competitions) publicly available, in the form of a paper describing the algorithmic details. This may be done anonymously, as part of the follow-up manuscript from the competition organizers, or (to avoid autoplagiarism) as part of a separately authored stand-alone manuscript. Winning participants will be required to open-source their code (for example, model weights, architecture, and relevant scripts to ensure reproducibility) upon journal request. This does not require the complete training code or training data. All participants (anonymously, but regardless of winning position) also agree to provide at least a single-sentence description of their methods (for example, “protein language model based on ESM2 and fine-tuned on antibody database XYZ”). By contributing, participants agree to this requirement for inclusion in the follow-on manuscript.
Future AIntibody competitions
We anticipate this to be the first of a series of AIntibody competitions, each comprising a set of challenges of increasing complexity that will provide opportunities for scientists to test, compare and improve their AI/ML models. Future contests are expected to evolve in complexity depending upon the outcome of this and other competitions, in parallel with the development of AI/ML use in antibody discovery and design. In the follow-on competitions anticipated below, the term ‘antibodies’ refers generically to either single-domain antibodies (also known as nanobodies) or conventional antibodies, with each competition addressing one of these formats. The challenges will include new tasks as well as repeat tasks (for example, Challenges 2 and 3 will be retained using different targets and NGS selection outputs) to ensure standardization, with ideas for future competitions proceeding as follows.
- 1.
Given an antibody sequence with known affinity to a target, generate candidates with improved affinities.
- 2.
Given an antibody sequence with known affinity to a target, with poor developability properties (for example, thermal stability, polyreactivity), generate candidates with equal or better affinities that lack the issues of poor developability.
- 3.
Given the sequence of a target with known structure, and structurally similar targets in the PDB, generate specific antibodies binding to the target.
- 4.
Given the sequence of a target with unknown structure, but similar targets in the PDB, generate specific antibodies binding to that target.
- 5.
Apply Challenge 3 above to a specific predefined epitope.
- 6.
Given a set of antibody sequences known to bind distinct epitopes on a given target, predict which antibodies bind to different epitopes.
- 7.
Given a set of antibody sequences known to bind distinct epitopes on a given target, predict which antibodies will allow sandwich binding.
- 8.
Given the sequence of a target, and a specific epitope within that target, generate de novo antibodies binding to that specific epitope.
- 9.
Given a set of diverse antibodies, predict their epitopes.
- 10.
Given the sequence of a target with known structure, generate antibodies binding to that target.
- 11.
Given an antibody sequence to a known human target epitope, create antibody designs that are cross-reactive to cynomolgus monkey and mouse with epitopes identical to or spatially close to the parental human epitope in their 3D structure.
- 12.
Create de novo or rationally guided antibody designs which do not bind any known targets (isotype controls).
To participate in AIntibody, please follow registration instructions at AIntibody.org. Participants may compete in one or more challenges. Registration will open on the publication date of this Correspondence (4 November 2024) and close on 23 January 2025. The datasets will be released to participants 30 days after publication and to the community upon publication of the results paper.
References
Linden, A. & Fenn, J. Understanding Gartner’s hype cycles (Strategic Analysis Report no. R-20-1971). Gartner Inc. 881423 (2003).
Google Scholar
Lewis Chinery, A. M. H. et al. Preprint at bioRxiv https://doi.org/10.1101/2024.03.26.586756 (2024).
Wossnig, L., Furtmann, N., Buchanan, A., Kumar, S. & Greiff, V. Drug Discov. Today 29104025 (2024).
Article CAS PubMed Google Scholar
Bender, A. et al. Nat. Rev. Chem. 6428–442 (2022).
Article PubMed Google Scholar
Moult, J. Curr. Opin. Biotechnol. 7422–427 (1996).
Article CAS PubMed Google Scholar
Senior, A. W. et al. Nature 577706–710 (2020).
Article CAS PubMed Google Scholar
Senior, A. W. et al. Proteins 871141–1148 (2019).
Article CAS PubMed PubMed Central Google Scholar
Jumper, J. et al. Nature 596583–589 (2021).
Article CAS PubMed PubMed Central Google Scholar
Almagro, JC et al. Proteins 793050–3066 (2011).
Article CAS PubMed Google Scholar
Almagro, JC et al. Proteins 821553–1562 (2014).
Article CAS PubMed Google Scholar
Watson, JL et al. Nature 6201089–1100 (2023).
Article CAS PubMed PubMed Central Google Scholar
Hie, BL et al. Nat. Biotechnol. 42275–283 (2024).
Article CAS PubMed Google Scholar
Harvey, E. P. et al. Nat. Common. 137554 (2022).
Article CAS PubMed PubMed Central Google Scholar
Li, L. et al. Nat. Common. 143454 (2023).
Article CAS PubMed PubMed Central Google Scholar
Lyu, J. et al. Preprint at bioRxiv https://doi.org/10.1101/2023.12.20.572662 (2024).
Ackloo, S. et al. Nat. Rev. Chem. 6287–295 (2022).
Article PubMed PubMed Central Google Scholar
Gathiaka, S. et al. J. Comput. Aided Mol. Des. 30651–668 (2016).
Article CAS PubMed PubMed Central Google Scholar
Guthrie, J. P. J. Phys. Chem. B 1134501–4507 (2009).
Article CAS PubMed Google Scholar
Hastie, K. M. et al. Science 374472–478 (2021).
Article CAS PubMed PubMed Central Google Scholar
Teixeira, AAR et al. MAbs 142115200 (2022).
Article PubMed PubMed Central Google Scholar
Ferrara, F. et al. Nat. Common. 13462 (2022).
Article CAS PubMed PubMed Central Google Scholar
Erasmus, MF et al. Sci. Rep. 1318370 (2023).
Article CAS PubMed PubMed Central Google Scholar
Raybould, M. I. J., Kovaltsuk, A., Marks, C. & Deane, C. M. Bioinformatics 37734–735 (2021).
Article CAS PubMed Google Scholar
Azevedo Reis Teixeira, A. et al. MAbs 131980942 (2021).
Article PubMed PubMed Central Google Scholar
Download references
Acknowledgements
We thank L. Wossnig for his generous insights and contributions to the manuscript. We also thank Bio-Techne for their gracious supply of the RBD antigen for this Benchmarking Study.
Ethics declarations
Competing interests
L.S., F.F., R.D., T.J.P., K.P.-S., S.D., M.F.E. and A.R.M.B. are employees of Specifica, an IQVIA business. O.H., C.L.-L. and Y.Q. are employees of Sanofi. H.G.N. and K.R. are employees of Incyte and stockholders. M. Shahsavarian is an employee of Eli Lilly. D.B. is an employee of Carterra. R.W. is an employee of Bonito Biosciences. C.M.D. discloses membership of the Scientific Advisory Board of Fusion Antibodies and AI proteins. P.M.T. is a member of the scientific advisory board for Nabla Bio, Aureka Biotechnologies, and Dualitas Therapeutics. P.M., E.V. and R.A. are employees of Novo Nordisk A/S. J.S. is an employee of OpenEye, Cadence Molecular Sciences. R.C.W. is an employee of AstraZeneca. A.E. and C.S. are employees of Merck Healthcare KGaA. S.B. is an employee of Evolutionary Scale. J.R. is an employee of Profluent Bio. S.F. is an employee of Alloy Therapeutics. V.B.K., S.M. and S.K. are employees of Takeda. P.K. is an employee of Cradle Bio. J.C.A. is an employee of GlobalBio. E.F., M. Stanton and C.P.G. are employees of Mosaic Biosciences. S.D.V. and F.T. are employees of Bayer A.G. All other authors declare no competing interests.
Rights and permissions
About this article

Cite this article
Erasmus, M.F., Spector, L., Ferrara, F. et al. AIntibody: an experimentally validated in silico antibody discovery design challenge. Nat Biotechnol (2024). https://doi.org/10.1038/s41587-024-02469-9
Download citation
Published:
DOI: https://doi.org/10.1038/s41587-024-02469-9







