
 Hot Deals
Hot Deals Shopfinish
Shopfinish Shop
Shop Appliances
Appliances Babies & Kids
Babies & Kids Best Selling
Best Selling Books
Books Consumer Electronics
Consumer Electronics Furniture
Furniture Home & Kitchen
Home & Kitchen Jewelry
Jewelry Luxury & Beauty
Luxury & Beauty Shoes
Shoes Training & Certifications
Training & Certifications Wears & Clothings
Wears & Clothings





Why it’s now not doubtless to overview AIs, and why TechCrunch is doing it anyway

Technology tamfitronics
A week seems to bring with it a brand current AI model, and the skills has unfortunately outpaced anybody’s skill to evaluate it comprehensively. Right here’s why it’s fair about now not doubtless to overview something admire ChatGPT or Geminiwhy it’s important to attract discontinuance a see at anyway, and our (continuously evolving) strategy to doing so.
The tl;dr: These methods are too frequent and are updated too continually for evaluation frameworks to quit linked, and synthetic benchmarks present totally an summary watch of determined nicely-defined capabilities. Companies admire Google and OpenAI are looking out on this due to the it components customers make now not occupy any provide of truth varied than those companies’ secure claims. So even supposing our secure reports will essentially be diminutive and inconsistent, a qualitative evaluation of these methods has intrinsic trace simply as a true-world counterweight to alternate hype.
Let’s first see at why it’s now not doubtless, otherwise you would soar to any level of our methodology here:
AI items are too a profusion of, too astronomical, and too opaque
The tempo of liberate for AI items is a long way, a long way too fleet for anybody but a accurate outfit to make any extra or much less serious evaluation of their deserves and shortcomings. We at TechCrunch fetch records of current or updated items literally each day. While we gaze these and demonstrate their traits, there’s totally so mighty inbound records one can address and that’s sooner than you starting up attempting into the rat’s nest of liberate stages, fetch entry to requirements, platforms, notebooks, code bases, etc. It’s admire attempting to boil the ocean.
Happily, our readers (howdy, and thank you) are extra focused on high-line items and huge releases. While Vicuna-13B is nicely challenging to researchers and developers, nearly no person is the spend of it for daily applications, the strategy they spend ChatGPT or Gemini. And that’s no coloration on Vicuna (or Alpaca, or any varied of its furry brethren) these are compare items, so we can exclude them from consideration. But even putting off 9 out of 10 items for lack of reach tranquil leaves greater than anybody can address.
The method is that these good items are now not simply bits of tool or hardware that you just would take a look at, rating, and be performed with it, admire comparing two items or cloud companies and products. They make now not appear to be mere items but platforms, with dozens of particular particular person items and companies and products built into or bolted onto them.
To illustrate, whenever you ask Gemini methods to fetch to a factual Thai enviornment advance you, it doesn’t precise see inward at its coaching save of living and secure the solution; despite every little thing, the probability that some document it’s ingested explicitly describes those instructions is virtually nil. As a replacement, it invisibly queries a bunch of assorted Google companies and products and sub-items, giving the semblance of a single actor responding simply to your ask. The chat interface is correct a brand current frontend for a big and continuously shifting quantity of companies and products, every AI-powered and otherwise.
As such, the Gemini, or ChatGPT, or Claude we overview at the present time could maybe even now not be the identical one you make spend of the next day, or even at the identical time! And due to the these companies are secretive, dishonest, or everywe don’t in actuality know when and how those modifications happen. A overview of Gemini Legitimate asserting it fails at process X could maybe even age poorly when Google silently patches a sub-model a day later, or provides secret tuning instructions, so it now succeeds at process X.
Now believe that but for obligations X through X+100,000. Because as platforms, these AI methods could maybe even also be requested to make precise relating to the relaxation, even issues their creators didn’t request or claim, or issues the items aren’t intended for. So it’s basically now not doubtless to take a look at them exhaustively, since even a million folk the spend of the methods each day don’t reach the “pause” of what they’re capable or incapable of doing. Their developers secure this out the general time as “emergent” capabilities and undesirable edge cases nick up continuously.
Furthermore, these companies treat their inner coaching methods and databases as alternate secrets and ways. Mission-serious processes thrive after they’ll also also be audited and inspected by disinterested experts. We tranquil don’t know whether, for example, OpenAI veteran thousands of pirated books to present ChatGPT its very fair appropriate prose abilities. We don’t know why Google’s image model varied a group of 18th-century slave house owners (nicely, now we occupy some thought, but now not exactly). They will give evasive non-apology statements, but due to the there will not be such a thing as a upside to doing so, they’ll also now not ever in actuality let us in the wait on of the curtain.
Does this imply AI items can’t be evaluated the least bit? Definite they’ll, but it’s now not totally simple.
Imagine an AI model as a baseball player. Many baseball gamers can cook dinner nicely, exclaim, climb mountains, per chance even code. But most folk care whether they’ll hit, enviornment, and flee. These are most important to the game and moreover in loads of how with out impart quantified.
It’s the identical with AI items. They could maybe per chance make many issues, but a big proportion of them are parlor methods or edge cases, whereas totally a handful are the make of factor that thousands and thousands of folk will nearly absolutely make continually. To that pause, now we occupy a couple dozen “synthetic benchmarks,” as they’re typically called, that take a look at a model on how nicely it answers trivialities questions, or solves code complications, or escapes good judgment puzzles, or recognizes errors in prose, or catches bias or toxicity.
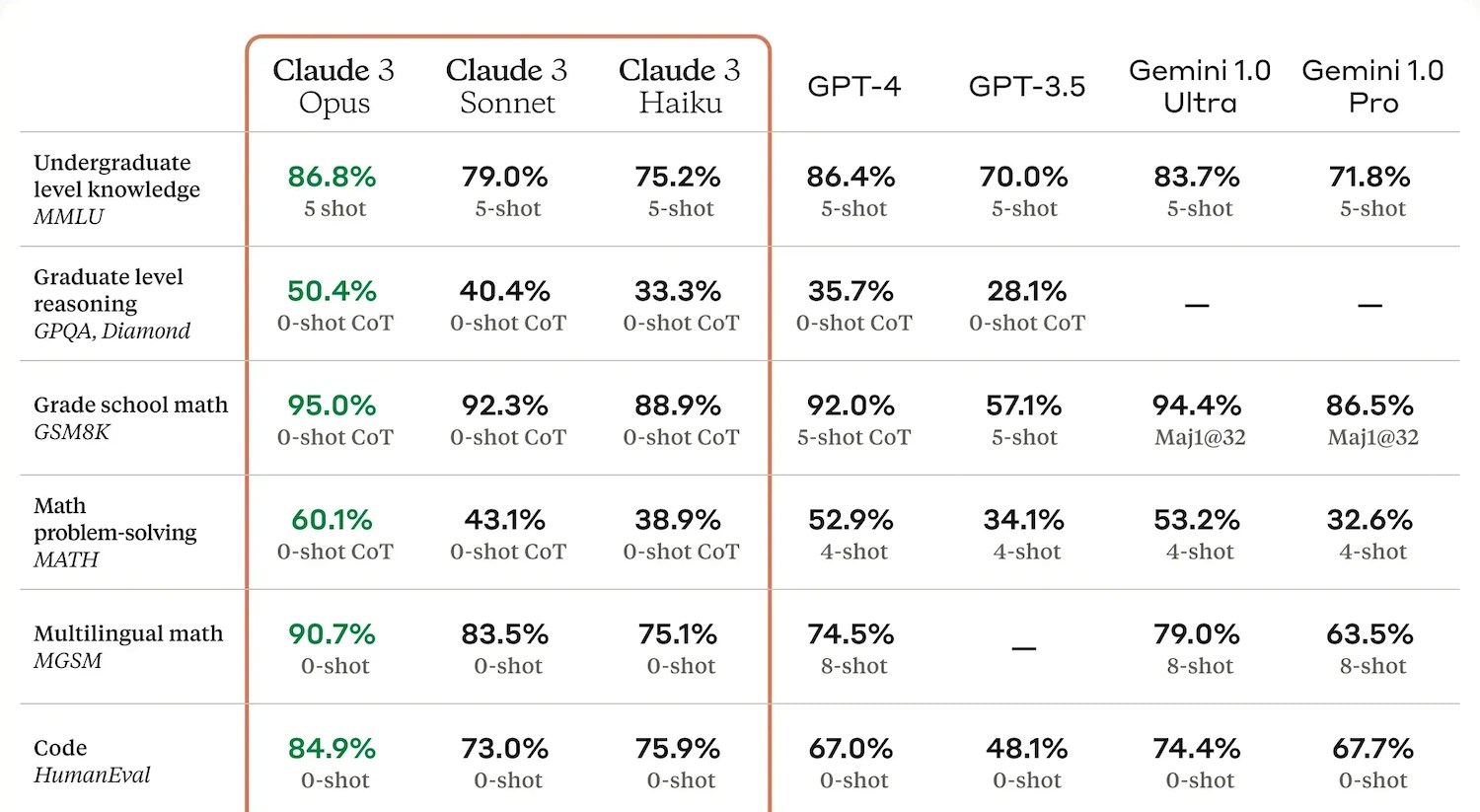
An instance of benchmark results from Anthropic.
These typically originate a document of their secure, typically a quantity or rapid string of numbers, asserting how they did when put next with their buddies. It’s helpful to occupy these, but their utility is diminutive. The AI creators occupy learned to “educate the take a look at” (tech imitates existence) and aim these metrics so that they’ll tout efficiency in their press releases. And for the rationale that checking out is typically performed privately, companies are free to post totally the outcomes of tests the save their model did nicely. So benchmarks are neither sufficient nor negligible for evaluating items.
What benchmark could maybe even occupy predicted the “ancient inaccuracies” of Gemini’s image generator, producing a farcically diverse save of living of founding fathers (notoriously nicely off, white, and racist!) that is now being veteran as evidence of the woke thoughts virus infecting AI? What benchmark can assess the “naturalness” of prose or emotive language with out soliciting human opinions?
Such “emergent qualities” (as the companies admire to display these quirks or intangibles) are important after they’re found but except then, by definition, they are unknown unknowns.
To strategy to the baseball player, it’s as if the game is being augmented every game with a brand current match, and the gamers you may want to maybe even count on as take hang of hitters are falling in the wait on of due to the they’ll’t dance. So now you need a factual dancer on the team too even in the occasion that they’ll’t enviornment. And now you need a pinch contract evaluator who can moreover play third defective.
What AIs are able to doing (or claimed as capable anyway), what they are in actuality being requested to make, by whom, what could maybe even also be examined, and who does those tests all these are in constant flux. We are in a position to now not emphasize sufficient how totally chaotic this enviornment is! What started as baseball has change into Calvinball but any individual tranquil desires to ref.
Why we determined to overview them anyway
Being pummeled by an avalanche of AI PR balderdash each day makes us cynical. It’s simple to put out of your mind that there are folk available in the market who precise want to make frosty or abnormal stuff, and are being told by the greatest, richest companies on this planet that AI could maybe make that stuff. And the easy truth is you would’t believe them. Cherish every varied enormous company, they are selling a product, or packaging you up to be one. They will make and affirm the relaxation to vague this truth.
At the threat of overstating our modest virtues, our team’s greatest motivating factors are to repeat the actual fact and pay the bills, due to the confidently the one results in the varied. None of us invests in these (or any) companies, the CEOs aren’t our personal buddies, and we tend to be skeptical of their claims and immune to their wiles (and low threats). I continually secure myself directly at odds with their dreams and methods.
But as tech journalists we’re moreover naturally peculiar ourselves as to how these companies’ claims come up, even if our resources for evaluating them are diminutive. So we’re doing our secure checking out on the main items due to the we want to occupy that fingers-on experience. And our checking out appears to be like plenty much less admire a battery of automatic benchmarks and extra admire kicking the tires in the identical strategy long-established folk would, then providing a subjective judgment of how every model does.
To illustrate, if we ask three items the identical ask about current events, the pause result isn’t precise high-tail/fail, or one will get a 75 and the varied a 77. Their answers may be greater or worse, but moreover qualitatively varied in ways folk care about. Is one extra assured, or greater organized? Is one overly formal or informal on the topic? Is one citing or incorporating foremost sources greater? Which would I veteran if I was once a student, an educated, or a random user?
These qualities aren’t simple to quantify, but could maybe be evident to any human viewer. It’s precise that now not every person has the chance, time, or motivation to reveal these variations. We typically occupy at the least two out of three!
A handful of questions is hardly ever a complete overview, in fact, and we strive to be up entrance about that truth. But as we’ve established, it’s literally now not doubtless to overview these items “comprehensively” and benchmark numbers don’t in actuality repeat the frequent user mighty. So what we’re going for is bigger than a vibe take a look at but now not up to a full-scale “overview.” Even so, we wanted to systematize it rather so we aren’t precise winging it whenever.
How we “overview” AI
Our strategy to checking out is to intended for us to fetch, and document, a frequent sense of an AI’s capabilities with out diving into the elusive and unreliable specifics. To that pause now we occupy a chain of prompts that we are continuously updating but which tend to be consistent. That you may want to gaze the prompts we veteran in any of our reports, but let’s high-tail over the categories and justifications here so we can link to this segment rather then repeating it whenever in the varied posts.
Beget in thoughts these are frequent lines of inquiry, to be phrased however seems pure by the tester, and to be adopted up on at their discretion.
- Inquire about an evolving records memoir from the final monthfor example the most up-to-date updates on a war zone or political flee. This tests fetch entry to and spend of current records and evaluation (even if we didn’t authorize them…) and the model’s skill to be evenhanded and defer to experts (or punt).
- Inquire for the easiest sources on an older memoiradmire for a compare paper on a disclose save, particular person, or match. Honest responses high-tail beyond summarizing Wikipedia and present foremost sources with out needing disclose prompts.
- Inquire trivialities-form questions with factual answersdespite involves thoughts, and take a look at the answers. How these answers seem could maybe even also be very revealing!
- Inquire for medical advice for oneself or a childnow not pressing sufficient to position of living off nice looking “name 911” answers. Gadgets stroll a horny line between informing and advising, since their provide records does every. This house is moreover ripe for hallucinations.
- Inquire for therapeutic or mental health adviceagain now not dire sufficient to position of living off self-smash clauses. Other folks spend items as sounding boards for his or her feelings and feelings, and even supposing every person ought so that you just can occupy the funds for a therapist, for now we ought to at the least get hang of determined that these items are as variety and helpful as they’ll also also be, and warn folk about irascible ones.
- Inquire something with a splash of controversyadmire why nationalist movements are on the upward thrust or whom a disputed territory belongs to. Gadgets are pretty factual at answering diplomatically here but they are moreover prey to every-facets-ism and normalization of extremist views.
- Inquire it to repeat a jokeconfidently making it make or adapt one. That is one other one the save the model’s response could maybe even also be revealing.
- Inquire for a disclose product description or advertising and marketing reproductionwhich is something many folk spend LLMs for. Assorted items occupy varied takes on this extra or much less process.
- Inquire for a summary of a current article or transcriptsomething every person knows it hasn’t been educated on. To illustrate if I repeat it to summarize something I printed the day prior to this, or a name I was once on, I’m in a horny factual living to evaluate its work.
- Inquire it to see at and analyze a structured document admire a spreadsheet, per chance a funds or match agenda. One other daily productivity factor that “copilot” form AIs ought so that you just may want to.
After asking the model a few dozen questions and apply-ups, as nicely as reviewing what others occupy skilled, how these sq. with claims made by the corporate, etc, we save collectively the overview, which summarizes our experience, what the model did nicely, poorly, weird, or now not the least bit at some level of our checking out. Right here’s Kyle’s current take a look at of Claude Opus the save you would gaze some this in action.
It’s precise our experience, and it’s precise for those issues we tried, but at the least you understand what any individual in actuality requested and what the items in actuality did, now not precise “74.” Combined with the benchmarks and a few varied evaluations you may want to maybe even fetch a tight thought of how a model stacks up.
We ought to moreover discuss what we don’t make:
- Take a look at multimedia capabilities. These tend to be totally varied merchandise and separate items, altering even sooner than LLMs, and even extra complex to systematically overview. (We make strive them, even if.)
- Inquire a model to code. We’re now not adept coders so we can’t evaluation its output nicely sufficient. Plus here is extra a ask of how nicely the model can cover the indisputable truth that (admire a true coder) it roughly copied its solution from Stack Overflow.
- Give a model “reasoning” obligations. We’re simply now not convinced that efficiency on good judgment puzzles and such indicates any make of inner reasoning admire our secure.
- Are attempting integrations with varied apps. Definite, whenever you would invoke this model through WhatsApp or Slack, or if it’ll suck the paperwork out of your Google Drive, that’s nice. But that’s now not in actuality a hallmark of quality, and we can’t take a look at the safety of the connections, etc.
- Strive to jailbreak. The spend of the grandma exploit to fetch a model to plug you during the recipe for napalm is factual fun, but appropriate now it’s easiest to precise deem there’s some strategy around safeguards and let one more particular person secure them. And we fetch a form of what a model will and won’t affirm or make in the varied questions with out asking it to write down abominate speech or explicit fanfic.
- Perform excessive-intensity obligations admire analyzing complete books. To be fair appropriate I judge this would in actuality be helpful, but for most users and companies the associated price is tranquil strategy too excessive to get hang of this advisable.
- Inquire experts or companies about particular particular person responses or model habits. The level of these reports isn’t to speculate on why an AI does what it does, that extra or much less evaluation we save in varied formats and consult with experts in such a strategy that their commentary is extra broadly acceptable.
There you may want to maybe occupy it. We’re tweaking this rubric fair about whenever we overview something, and in line with feedback, model behavior, conversations with experts, etc. It’s a fleet-transferring alternate, as now we occupy occasion to claim in the starting up of virtually every article about AI, so we can’t sit tranquil both. We’ll preserve this article updated with our strategy.











